
Có thực sự tồn tại một hệ thống phân tán đủ 3 yếu tố “Ngon bổ rẻ”? Định lý CAP và ứng dụng. Trong bài viết này, chúng ta sẽ khám phá các khái niệm cơ bản của tính nhất quán, tính sẵn sàng và khả năng chịu phân mảnh trong hệ thống phân tán, cùng với mối quan hệ của chúng với định lý CAP.
Đồng thời, chúng ta sẽ tìm hiểu cách mà Redis, MongoDB & Amazon RDS Multi-AZ ứng dụng nguyên tắc này.
I. Khái niệm
Tính nhất quán (Consistency)
Trong hệ thống phân tán, tại cùng một thời điểm, dữ liệu mà các client nhìn thấy phải hoàn toàn giống nhau. Bất kể là dữ liệu được lấy từ node nào.
Để đạt được điều này, phải thực hiện đồng bộ dữ liệu cho tất cả các node.
Consistency means that all clients see the same data at the same time, no matter which node they connect to. For this to happen, whenever data is written to one node, it must be instantly forwarded or replicated to all the other nodes in the system before the write is deemed ‘successful.’
Ví dụ: Trong hệ thống ngân hàng giao dịch được xem là nhất quán nếu
Balance[A] = $100, A thực hiện chuyển tiền $50
Trường hợp hệ thống báo thành công và cập nhật Balance[A] = $50
Trường hợp hệ thống báo thất bại và giữ nguyên Balance[A] = $100
A kiểm tra trên tất cả các thiết bị và nhận được cùng 1 kết quả như kì vọng.
Tính sẵn sàng (Availability)
Hệ thống phải đảm bảo mọi request từ client đều nhận được phản hồi. Bất kể là phản hồi đó có nhất quán hay không.
Availability means that that any client making a request for data gets a response, even if one or more nodes are down.
Ví dụ: 2 người dùng nhấn like 1 video youtube, lượt like trên cả 2 thiết bị đều chỉ tăng thêm 1, cho người dùng biết họ đã like video.
Trong trường hợp này tính sẵn sàng được ưu tiên vì số lượng like chính xác không quá quan trọng, điều quan trọng là người dùng biết mình đã like video.
Khả năng chịu phân mảnh (Partition Tolerant)
Hệ thống phải tiếp tục hoạt động khi xảy ra sự cố gây mất kết nối giữa các node với nhau.
Partition tolerance means that the cluster must continue to work despite any number of communication breakdowns between nodes in the system.
Ví dụ: Hệ thống cloud của Amazon hoàn toàn có thể hoạt động được ngay cả khi có sự cố phân chia các trung tâm dữ liệu ở các khu vực khác nhau.
CAP Theorem
CAP Theorem, còn được gọi là Brewer's theorem, là một nguyên lý trong lĩnh vực hệ thống phân tán, được công bố bởi Eric Brewer vào năm 2000.
Nó nêu rõ rằng một hệ thống phân tán không thể đồng thời đảm bảo cả ba thuộc tính trên.
Thông thường hệ thống thường phải lựa chọn đánh đổi giữa C (Tính nhất quán) và A (Tính sẵn sàng) vì P (Khả năng chịu phân mảnh) rất khó kiểm soát một cách triệt để.
II. Redis và CAP theorem
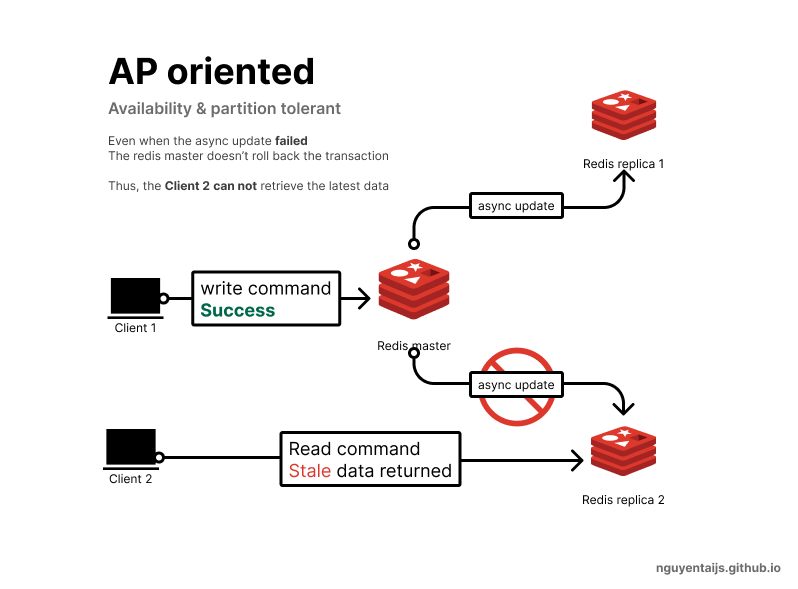
Trong kiến trúc clustered Redis, khi có một thao tác ghi trên Redis master, các Redis replica sẽ được cập nhật dữ liệu tương ứng.
- Redis master thực hiện ghi trên node của mình
- Nếu thành công trả về kết quả cho client
- Đồng thời
Redis mastercũng gửi yêu cầu ghi sang cácreplica
Vì quá trình này diễn ra bất đồng bộ, nên nếu Redis master mất kết nối đến một trong số các replica, thao tác ghi trên master sẽ không được đồng bộ với replica đó.
Tuy nhiên, Redis master vẫn xác nhận thao tác ghi thành công. Do đó, dữ liệu trả về từ các Redis replica sẽ là dữ liệu cũ.
Điều này cho thấy rằng Redis (với cấu hình mặc định) ưu tiên hai tiêu chí AP (Availability và Partition Tolerance).
Hệ quả của cách làm này là hệ thống sẽ luôn nhận được phản hồi từ Redis nhưng tồn tại rủi ro nếu client access dữ liệu của replica bị mất kết nối.\
Các bạn có tự hỏi làm cách nào để Redis tái đồng bộ lại các replica sau khi quá trình phân mảnh tạo ra không? Hẹn các bạn ở 1 bài viết khác nhé
III. MongoDb và CAP theorem
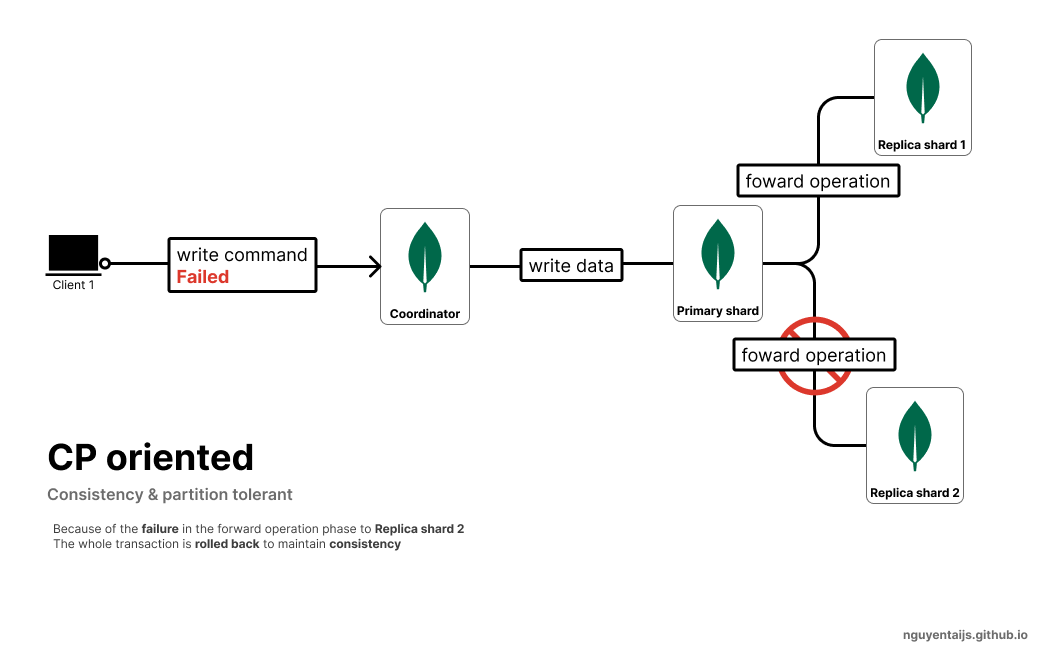
Trong MongoDB, cũng có một cách cấu hình tương tự để đồng bộ dữ liệu từ primary shard sang các replica.
Khi có một thao tác ghi trên primary shard, các hành động sau sẽ được thực hiện:
- Validate
operationđầu vào, reject nếu sai cấu trúc - Thực thi
operationtrênprimary shard - Chuyển tiếp
operationcho toàn bộreplicaliên quan - Chỉ khi toàn bộ
replicathực hiện thành công và phản hồi lại choprimary shard, lúc nàyprimary shardmới xác nhận request của client là thành công.
Như vậy, khác với Redis, MongoDb hướng tới 2 tiêu chí CP (Consistency & Partition tolerant)
Client sẽ không thể ghi dữ liệu cho đến khi MongoDb xác nhận quá trình ghi đến tất cả các node thành công.
Việc này đảm bảo tính nhất quán của dữ liệu, tối đa độ tin cậy đối với một CSDL.
IV. Amazon RDS Multi-AZ và CAP theorem
Amazon RDS (Relational Database Service) là dịch vụ do Amazon cung cấp để triển khai cơ sở dữ liệu quan hệ trên cloud. Amazon RDS tương thích với các cơ sở dữ liệu quan hệ phổ biến như: PostgreSQL, Mysql, MariaDB, SQL Server cho phép sử dụng mà tích hợp dễ dàng trên cloud. Kiến trúc của Amazon chia thành nhiều region, mỗi region có nhiều Availability Zone (AZ). Thông thường khách hàng sẽ lựa chọn triển khai dịch vụ trên nhiều AZ hoặc region vì các lợi ích mà nó mang lại. Amazon RDS cung cấp một dịch vụ như vậy có tên là Amazon RDS Mutli-AZ. Cơ chế mà Amazon RDS multi-AZ sử dụng để tăng khả năng chịu lỗi và đảm bảo tính nhất quán là Synchronous replication
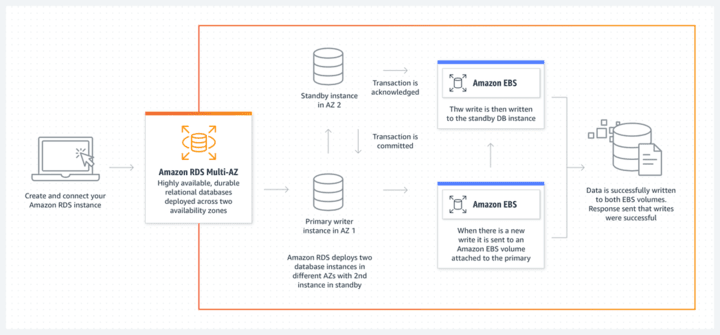
Cơ chế Synchronous replication
Synchronous replication học tập cách MongoDB xử lý đồng bộ dữ liệu giữa các node. Cụ thể như sau
- Primary instance nhận yêu cầu ghi từ client
- Primary instance ghi dữ liệu vào
transaction logcủa primary instance - Primary instance thực thi lệnh ghi
- Chuyển
transaction logsang replica instance - Replica instance ghi dữ liệu vào
transaction logcủa mình - Replica instance thực thi lệnh ghi
- Replica instance gửi xác nhận (ACK) cho primary instance rằng thay đổi đã được thực thi thành công
- Primary instance gửi phản hồi hoàn thành transaction về client
Nhờ có quá trình trên mà RDS Multi-AZ có thể tự động failover sang replica khi phát sinh sự cố trên primary. Đánh đổi cho tính nhất quán là việc phải chờ đợi đồng bộ thao tác từ các node làm tăng độ trễ và ảnh hưởng đến throughput (giảm availability).
Lựa chọn này phù hợp với các hệ thống yêu cầu tính nhất quán cao và không chấp nhận mất mát dữ liệu.
Bài viết lấy cảm hứng từ Grokking Webinar - Sự đánh đổi giữa tính Consistency và Availability trong các database cluster
Cảm ơn Grokking đã có những buổi chia sẻ sâu và chất lượng.